

DCI over Ethernet enables high-speed, low-latency connectivity between data centers, supporting AI workloads and large-scale data transfer.
Carrier Ethernet for AI
Carrier Ethernet has underpinned business connectivity for more than two decades. Now, as AI workloads proliferate across data centers, cloud platforms, colocation facilities, and enterprise edge sites, the technology is being reimagined for a new era. The connectivity demands of distributed AI workloads are fundamentally different: higher capacity, tighter latency bounds, near-zero packet loss, and end-to-end service assurance across multiple provider domains. RAD has been a key contributor to Carrier Ethernet standards since the early days of MEF, and continues to lead today with a portfolio purpose-built for the requirements of networking for AI.

Table of Contents
What is Carrier Ethernet for AI?
Carrier Ethernet for AI refers to the evolution of CE standards, performance specifications, and networking technology to meet the specific demands of AI workloads. Where traditional Carrier Ethernet was engineered for business connectivity with assured , Carrier Ethernet for AI extends those foundations to meet the far higher throughput and stricter latency demands that GPU-intensive workloads require, as well as the fundamentally more dynamic traffic behavior they produce.
The technology preserves the core properties that made Carrier Ethernet the preferred transport layer for enterprise services: SLA-based performance assurance, rich OAM and performance monitoring, hierarchical quality of service, multi-domain service consistency, and standards-based interoperability. What changes are the performance envelope and the degree of intelligence built into the network.

Mplify, formerly MEF, has formalized this evolution through the Carrier Ethernet for AI certification program. The program updates performance specifications well beyond traditional MEF 3.0 service definitions and introduces new certifications that validate whether Carrier Ethernet platforms and services can meet AI’s transport requirements. Data Center Interconnect (DCI) is the first scenario addressed under the program, given its central importance to distributed AI architectures.
What Does Networking for AI Demand from the Network?
AI workloads behave differently from traditional enterprise applications. Training runs move enormous datasets between compute sites. Real-time inference is latency-sensitive in ways that email or ERP traffic is not. GPU clusters represent significant capital investment, and they require sustained high-throughput connections to stay fully utilized. And AI architectures are increasingly distributed, spanning point-to-point, point-to-multipoint, and multipoint-to-multipoint traffic patterns within a single deployment.
Beyond model training and inference, the rapid rise of AI agents introduces a new and distinct networking challenge. Unlike monolithic AI workloads, AI agents operate as distributed, autonomous entities that continuously communicate with other agents, tools, data sources, and orchestration frameworks. Their traffic patterns are highly dynamic, bursty, and interactive, often blending control-plane signaling with data-plane exchanges in real time.
Agent-based architectures generate short-lived, latency-critical flows rather than long, steady streams. An AI agent coordinating with peer agents or invoking external services must receive timely responses to maintain reasoning continuity, decision accuracy, and task execution speed. Even small latency spikes or jitter can cascade into degraded agent performance, delayed actions, or incorrect decision paths.
Packet loss during a training run can degrade model quality or force costly re-transmission, cutting directly into the return on GPU investment. Supporting AI communications therefore demands networks that can sustain low latency, ultra-low jitter, rapid flow setup, and fine-grained QoS across multi-domain environments, while scaling data rates at 100G, 400G, or 800G to support massive amounts of data and millions of micro-interactions per second. As AI systems evolve from static pipelines to living, communicating ecosystems, the network becomes a critical enabler of agent intelligence, autonomy, and reliability, not merely a bandwidth provider.
Why Carrier Ethernet for Networking for AI
- SLA-based performance assurance for AI traffic across provider domains
- Operational visibility through OAM and performance monitoring
- Hierarchical QoS to isolate AI from other services on the same link
- Multi-domain service consistency across carriers and cloud on-ramps
- Standards-based interoperability
- Flexible automation and on-demand bandwidth scaling
Enterprise AI adoption, not hyperscaler build-out, will drive the next wave of network demand. CSPs that can deliver premium, AI-optimized Carrier Ethernet services are positioned to capture that opportunity.
What is Data Center Interconnect for AI?
Data Center Interconnect for AI refers to the high-capacity, low-latency links that connect data centers running AI workloads, enabling training, inference, and large dataset traffic to move between sites.
Historically, DCI relied on dark fiber leased from carriers. AI-driven DCI raises the bar considerably. The links must carry traffic at 100G or 400G with predictable latency and enforceable SLAs that prevent AI traffic from being disrupted by contending workloads. Security is equally important, since the data in transit frequently includes proprietary model weights and sensitive training datasets. And the operational demands of managing these connections at scale require real-time telemetry and zero-touch provisioning capabilities that go well beyond what traditional DCI infrastructure provides.
CSPs that can offer SLA-assured, high-capacity DCI over Carrier Ethernet are well-placed to serve this market.
What is RAD’s Carrier Ethernet for AI DCI Solution?
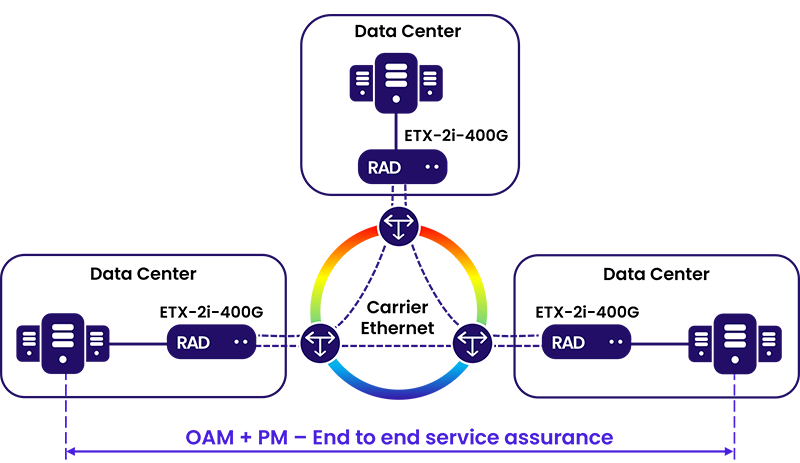
RAD’s ETX-2i-400G is a purpose-built platform for AI-era data center interconnect. It delivers 400G Carrier Ethernet demarcation and aggregation with the ultra-low latency and assured performance that GPU-intensive workloads require.
The platform enforces SLAs through hierarchical QoS, isolating AI traffic from other services and preventing bursty training or inference workloads from degrading latency-sensitive traffic on the same link. Intelligent buffering prevents congestion events that cause packet loss and GPU underutilization. Fat-pipe detection enables proactive traffic management before congestion affects performance.
Security is built in at line rate. MACsec encryption protects data in transit without introducing latency overhead. The ETX-2i-400G is designed with a crypto-agile architecture that includes Post-Quantum Cryptography (PQC) and Quantum Key Distribution (QKD) support, protecting sensitive AI assets against both current and emerging threats.
Operationally, the platform supports Zero-Touch Provisioning (ZTP), NETCONF/YANG, and SDN integration, enabling carriers to provision and manage DCI services at scale with minimal manual intervention.
The ETX-2i-100G extends the same architecture to 100G deployments, providing CSPs with scalable options across different capacity tiers.
RAD’s ETX-2i platform was developed in direct alignment with the use cases Mplify is prioritizing under its Carrier Ethernet for AI program. DCI is the first scenario the program addresses, and purpose-built DCI performance is what the ETX-2i platform was designed to deliver.
How Can CSPs Monetize Carrier Ethernet for AI?
The shift to massive AI adoption by enterprises creates a major business opportunity for service providers that goes beyond carrying more traffic. Historically, CSPs in the DCI market competed primarily on dark fiber pricing, with limited room to differentiate. Enterprise AI changes this dynamic.
Businesses scaling AI across distributed environments need managed connectivity with guaranteed performance, not just raw bandwidth. That requirement opens several distinct revenue streams.
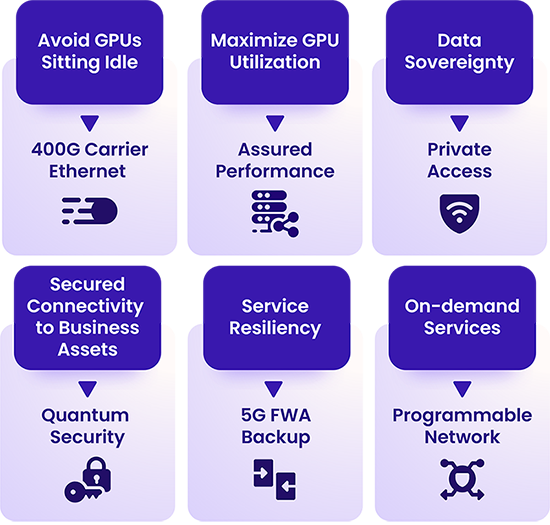
Premium DCI services are the most immediate opportunity. Rather than competing on dark fiber pricing, CSPs can offer SLA-assured 100G and 400G interconnect with active performance monitoring, traffic isolation, and committed latency. Enterprises running AI workloads have a measurable cost to network underperformance: idle GPU time directly erodes the return on significant infrastructure investment. Services that protect GPU utilization command a premium.
At the carrier edge, bandwidth-on-demand models convert AI traffic from a capacity planning challenge into a billing opportunity. Enterprises need connectivity that scales with their workloads rather than a fixed pipe provisioned for peak demand. Usage-based or tiered pricing aligned with AI consumption patterns lets CSPs grow revenue alongside their customers’ deployments.
Security services offer another differentiation point. As enterprises move sensitive model weights and training data across the network, quantum-safe encryption and compliance-grade data sovereignty controls become capabilities enterprises will pay for rather than manage themselves.
What is Carrier Edge Networking for AI Business Services?
The carrier edge is where enterprise sites connect to the CSP network and, through it, to cloud-hosted GPU resources, remote data centers, and AI service providers. As AI becomes central to business operations, that connection becomes a direct dependency in ways it never was before.
The connectivity requirements at the carrier edge for AI differ from traditional business services in several important ways. Bandwidth must scale on demand: a training burst or spike in inference traffic should be able to claim additional capacity without manual intervention, then release it when no longer needed. Jitter and latency must be controlled so that AI traffic does not degrade the SLA of other enterprise services running on the same link.
AI agent–based business services further amplify the importance of the carrier edge. Unlike human use of AI-based applications, AI agents operate as distributed, autonomous actors that continuously interact with users, peer agents, models, enterprise systems, and external services. These interactions generate large volumes of short-lived, bi-directional, latency‑sensitive flows that must be handled close to the enterprise ingress point.
In logistics and manufacturing, AI agents increasingly coordinate fleets of autonomous guided vehicles (AGVs), autonomous storage vehicles, and robotic systems, continuously exchanging control signals, sensor data, and task updates with local systems and cloud‑based optimization engines. These interactions are highly latency‑sensitive and often bidirectional, requiring predictable performance at the point where the enterprise connects to the network.
At the carrier edge, the network must therefore support fast connection setup, fine-grained traffic classification, strict traffic isolation, and real-time prioritization to ensure agent control traffic and decision loops are not delayed or disrupted by bulk data transfers.
Data sovereignty is a growing concern for enterprises running AI on sensitive or regulated data. Carrier Ethernet provides the control and visibility needed to enforce policies over the physical path data takes in motion, something that cloud-native connectivity often cannot guarantee.
This elevates the importance of the carrier edge, where service resiliency, policy enforcement, security and predictable SLA-backed performance are essential to safely deploying AI‑driven business application and services across distributed sites.
What is RAD’s Carrier Edge for AI Solution?
RAD’s carrier edge portfolio brings programmability and intelligence to the point where enterprise sites connect to the CSP network. Its Carrier Ethernet devices enable service providers to deliver certified Mplify services, leveraging hierarchical traffic management that priorities mission-critical data, while keeping AI workloads from affecting other latency-sensitive enterprise services.
Its programmable Carrier Ethernet devices support Ethernet On‑Demand, allowing bandwidth to scale dynamically for dataset ingestion, training bursts, or inference spikes, without requiring manual provisioning at each change.
Security at the edge is addressed with the same crypto-agile approach used in RAD’s DCI platforms. PQC and QKD support protect data moving to remote GPU clusters, while IPsec-based access enables secure connectivity for SASE environments and remote workers accessing GPU resources.
RAD’s custom ASIC family, purpose-built for its Carrier Ethernet portfolio, integrates an on-chip processing unit and on-chip memory designed for low-latency, real-time, on-device AI inference. This enables AI-native networking capabilities directly in the data plane, including real-time anomaly detection and adaptive traffic optimization, without relying on external compute.
RAD devices generate rich OAM and telemetry data that is structured and exposed through the Model Context Protocol (MCP). This gives AI agents the operational context they need to automate root-cause analysis, anticipate service impacts before they affect end users, and optimize network performance in real time.
How is RAD Shaping Carrier Ethernet for AI Standards?
RAD’s involvement in Carrier Ethernet standards goes back to the early days of MEF. The company’s technology contributions helped shape foundational standards that defined Carrier Ethernet as a service framework, from E-Line, E-LAN and E-Access service definitions to performance attributes and OAM specifications. That work established the interoperability and SLA assurance mechanisms that underpin Carrier Ethernet’s reputation as a reliable business transport technology.
As MEF has evolved into Mplify, RAD continues to contribute to the next chapter of that standards work.
RAD’s innovation roadmap is fully aligned with what the Carrier Ethernet for AI program validates. The ETX-2i and quantum-safe security capabilities are all engineered to meet the performance attributes the certification tests for. As a technology provider contributing platforms to the Carrier Ethernet for AI ecosystem, RAD is not just aligning with the standard. It helps to define what AI-ready Carrier Ethernet looks like in practice.
Carrier Ethernet for AI Resources
Carrier Ethernet for AI Use Cases
 Data Center Interconnect
Data Center Interconnect
 Carrier Ethernet for Business Services
Carrier Ethernet for Business Services
Carrier Ethernet for Business Services
Easily plan, deploy, provision, and maintain SLA-based business services over any access: fiber/copper/TDM/mobile, with Carrier Ethernet access and aggregation supporting rates up to 1/10/25/100G/400G*. Solution for business class access to internet, cloud and VPN services.